
Mind-Blowing VALL-E: Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
The future of speech synthesis: VALL-E’s zero-shot text-to-speech synthesis capabilities
Follow me on social media
Projects I’m currently working on


VALL-E (Voice-Activated Language Learning Entity) is a revolutionary new type of neural codec language model that has the ability to perform zero-shot text-to-speech synthesis. This means that VALL-E can generate speech in any language, without the need for any prior training or data in that language.
Model Overview
VALL-E is based on a neural network architecture known as a transformer model. This type of model is particularly effective at handling large amounts of data, such as text, and is able to learn patterns and relationships within the data to make predictions or generate new output.
The key to VALL-E’s ability to perform zero-shot text-to-speech synthesis is its use of multi-language encoders. These encoders are able to take in text in any language and convert it into a common representation, or “code,” that can then be used to generate speech in that language. This allows VALL-E to understand and generate speech in any language, without the need for any specific training data in that language.
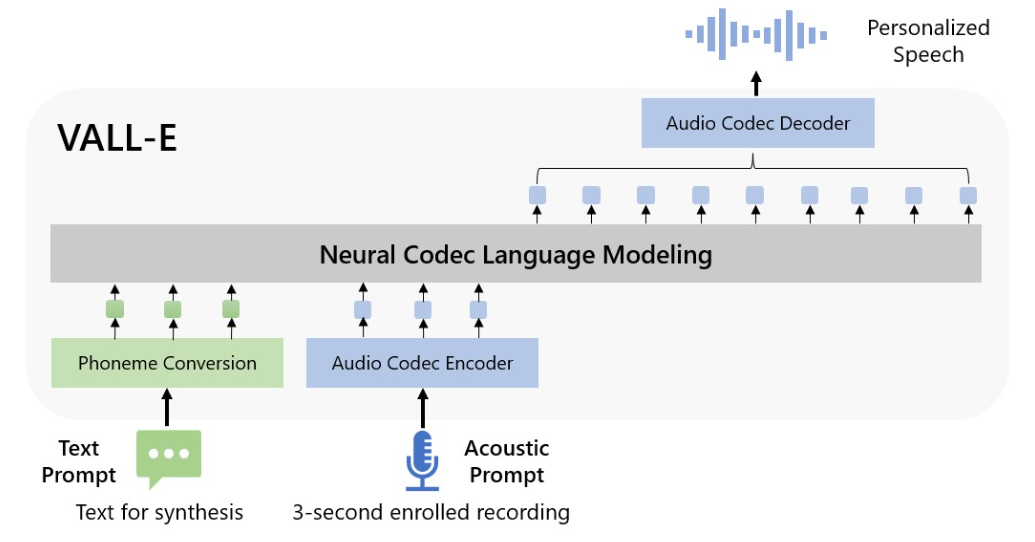
One of the key benefits of VALL-E is its ability to generate natural-sounding speech in any language. This can be particularly useful in a number of different fields and applications, such as language learning, language translation, and speech-enabled virtual assistants.
For example, in language learning, VALL-E could be used to generate speech in the target language for learners to practice listening and speaking. In language translation, VALL-E could be used to generate speech in the target language for text that has been translated from another language. And in speech-enabled virtual assistants, VALL-E could be used to generate speech in any language for users to interact with the assistant.
Advantages
In addition to its ability to generate speech in any language, VALL-E also has the ability to learn and adapt to new languages over time. This means that as more data and training examples become available in a particular language, VALL-E can continue to improve its ability to generate speech in that language.
Overall, VALL-E is a powerful and versatile neural codec language model that has the ability to perform zero-shot text-to-speech synthesis in any language. Its potential applications range from language learning and translation to speech-enabled virtual assistants and beyond.
Use Cases
Similar neural codec language models that have been developed include Google’s Tacotron and Baidu’s Deep Voice. These models also have the ability to generate speech from text input and have been used in a variety of applications such as speech synthesis for virtual assistants and language translation. However, VALL-E’s unique feature of being able to perform zero-shot text-to-speech synthesis sets it apart from these models.
Conclusion
In conclusion, VALL-E is a cutting-edge neural codec language model that has the ability to generate natural-sounding speech in any language, without the need for any prior training or data in that language. Its potential applications are numerous and its ability to learn and adapt to new languages over time makes it a highly valuable tool in a variety of fields. As the field of neural codec language models continues to evolve, we can expect to see even more advanced and versatile models like VALL-E being developed in the future.
